
We support proxy, why do we need OpenAthens?
Our resource hub is full of educational content and raises awareness of the three key issues around IP-based access: security, poor user experience, and lack of personalization.
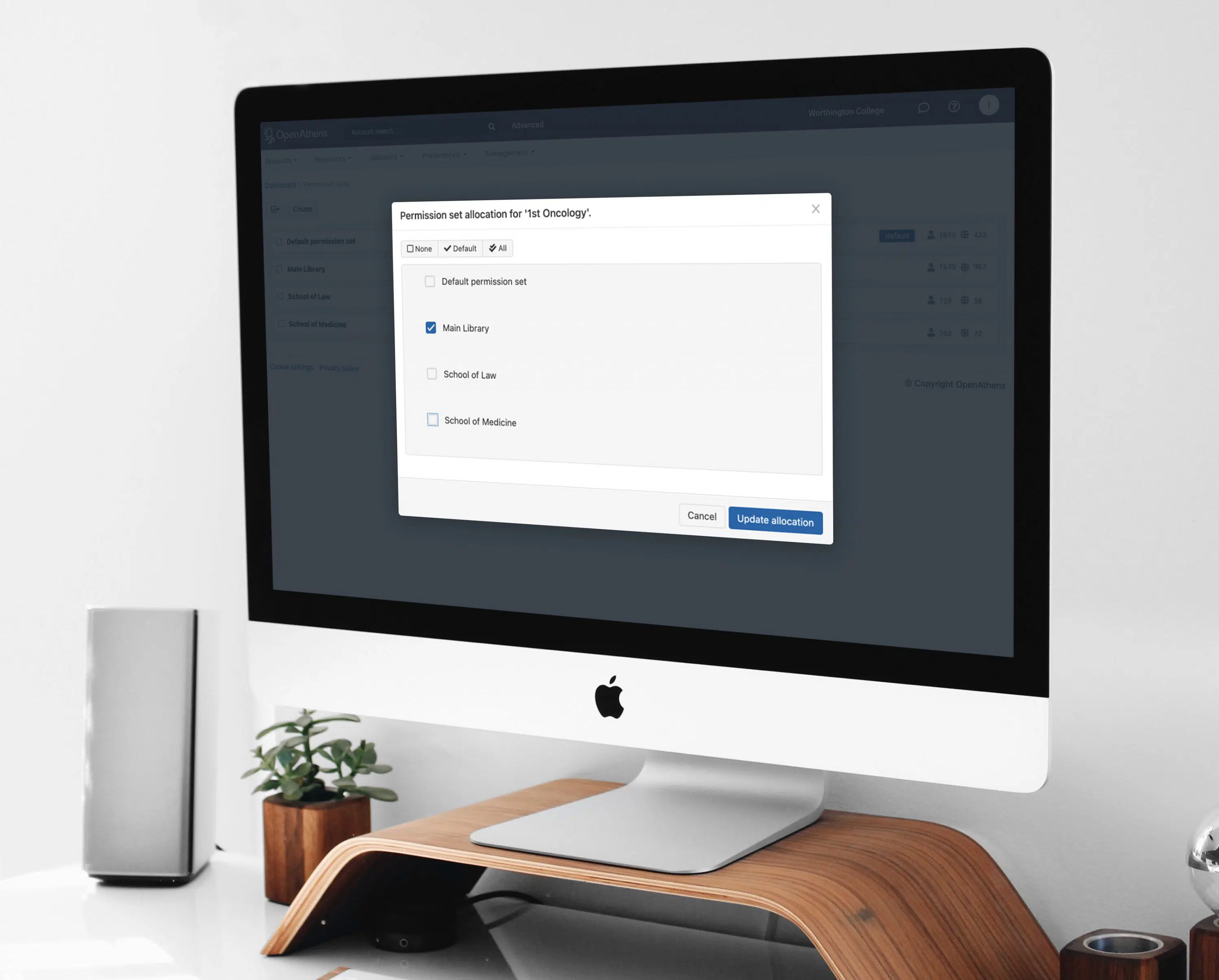
We make accessing knowledge through a single sign-on easy.
We help more than 3,000 organizations with 8 million users in over 80 countries have access to the knowledge they want when they want it.
Our resource hub is full of educational content and raises awareness of the three key issues around IP-based access: security, poor user experience, and lack of personalization.
The cyber security threat landscape is always evolving, and attacks are becoming more prevalent and sophisticated.
Explore our collection of educational resources designed to empower you with the knowledge and tools to safeguard yourself and your organization from cyber threats. Join us in building a safer, more secure digital future.
Don’t take our word for it! Read customer success stories about setting up, integrating and using OpenAthens.


There’s lots of ways to stay in touch with us and our community of customers.
OpenAthens has been providing remote access and authentication solutions for over 25 years. Used worldwide by over 3,000 academic, healthcare, corporate research libraries, publishers, and service providers to provide access to knowledge. We’re based in the UK and are a part of Jisc.

